imgSearch
0.概述
本文是个人开源项目 ImgSearch 的产出,各个模块遇到的问题及优化策略和一些较重要的算法。
1.图片下载与读取
1.0 下载
为效率计,采用并行的下载方式,同样地,为以后并行读取、处理作准备,需要考虑图片存储方式
1.1 存库设计
为高效的存储和读取,摒弃一些不必要的功能,采用的库是 leveldb 这样一个键值对小型数据库 (项目中后期遇到了读取效率问题, 作了较多的优化考虑。反思:leveldb 可能不太适合此项目的一次写多次读的场景)
图片库的键是图片名字,值是图片源数据。为后续并行处理,图片名的设计为线程 id + seqence number. 又为了显示方便,线程 id 设置为 A, B, C...,图片名格式为:A0000001。存储空间上,图片名占 4 个字节。逻辑上,每个线程可存储最多 1000 万个图片:这已经足够了,进一步地通过分库可作横向无限扩充。并行下载,并行存储,多个线程并行写入,这是 leveldb 的强项。
1.2 性能考虑
读库时遇到了以下性能问题:
- 读库模式是:各线程通过 id 定位到各线程处理点,往后遍历:线程 A 处理 Range[A-prefix : B-prefix),线程 B 处理 Range[B-prefix : C-prefix) ......
性能问题:读库处理时(密集型 CPU 运算),发现 IO 占比过高,CPU 使用率较低:16 个 go routine 并行并未占满 CPU,使用率只占到 30%。
优化:首先,各线程使用 DB::Iterator 顺序访问,遵守逻辑层的顺序,而非物理存储层面的顺序:若每个线程处理的相领两个图片所在的 leveldb::block 都不同,这意味着 leveldb 每次都需要切换 block 执行读:最直接地,block cache 会被换入后,读取一个键,再换出,不停重复这个过程。其次,由于在之前入库时多个线程同时写,各个线程相互干扰,无法保障各线程入库内容在物理存储层面的有序性。基于以上两点,优化写入模式为:各线程使用一个缓存,蓄满后转化为 Batch 一次性写入。然而很遗憾的是,这并没有多少改善, CPU 使用率仍然为 30 %。
进一步优化:复盘上面的模型,难道问题出现在,leveldb::Batch 写入,并不能保证各线程的数据在相同的 block?确实:由于 leveldb 没有事务的概念,并不能保证一个线程的 Batch 在写入的块,不被另一个线程的 Batch 写入插入打乱。因此,我们需要进一步地优化:同一时间,只能有一个 goroutine 写入。我们增加一个二级缓存,接收各线程的一级缓存数据,若一级缓存满了则加入二级缓存(加锁),若二级缓存满了则入库。我们将二级缓存设置的大一些就能减少线程的等待时间(因为 leveldb 写入速度远快于读取并处理的速度, 故等待时间忽略不计)。再次很遗憾,还是没有多少改善。
更进一步:经过上面的优化,我们应该可以肯定各线程的数据确实在同一个物理 block 里面。因此,读取效率低的原因就隐藏在 leveldb 怎么处理同一个块中数据的读取上。深入 leveldb :iterator 顺序遍历涉及到这几个内部迭代器: tablecache, memtable, immtable。tablecache 包装了各第0层文件的迭代器和其它层次各层的迭代器,它们内部会读写一个全局的 blockcache:它正是关键点:若 blockcache 大小设置的小于 n 个线程所需要的大小则会导致多个线程同时竞争这个 blockcache: 各线程换入的缓存可能立即会被其它线程换出,相互掣肘导致所有线程读取效率低。知道了这一点,n 个 goroutine 场景下,我们将 leveldb 的 blockCacheSize 设置为 (n+1)*blockSize,多设置一个 blockSize 以应对余数或其它边边角角。经过这一次优化, CPU 使用率如期升到了 100%
2.图片处理
图片处理包括三方面的内容,一是下载的图片有些是非标准格式的 jpg,导致后续处理有错误,因此需要修复。二是将图片数据转化为我们程序处理的数据。三是图像图形处理算法,用于识别,建模等等。
2.1 图片修复
预期是 jpeg 文件,通过判断文件魔数(起始两个字节),发现确实是 0xFFD8。最后两个字节是 0xFFD9。它们是 jpeg 的标准。然而在使用 imgo 库读取图片内容时,发现读取失败: invalid marker。具体也不报说是哪个 marker 有误。尝试使用 java 的 jpeg 库读取:不同图片报出来的 invalid marker 后附加的数字不一样,猜测应该是在某些标记处的值不符合预期。
因此需要了解 jpeg 图片的基本格式:

很明显,当 jpeg 二进制数据 0xFF 后若跟了非标准的字节则会被算作无效 marker。
具体如下:
1)非法的 markder,根据 image.jpeg 库的 reader.go 中描述的 markder,无效的 marker 均小于 C0
2)Corrupt JPEG data: 'n' extraneous bytes before marker 0xd9 ,意思是说marker: 0xd9 的前面有 n 个多余的字节
经过排查,发现 1) 会导致解析错误,而 2) 只是一个告警,不会报错。所以我们的解决办法即是删除不合法的 marker 的第一个字节:0xFF
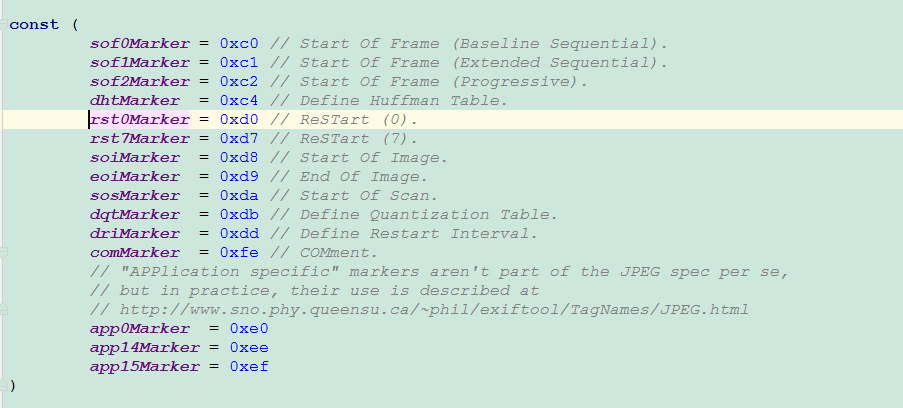
image.jpeg/reader.go 文件关键位置:
验证码识别
这是最终目标:识别出下面验证码应该
最初的想法是传统的想法,识别出文字,与图片关联。
kemans
运用 kmenas 算法,识别文字
- 1.根据汉字在图片中的规律,使用窗口扫描灰度化后的图片,若这个窗口内含有的像素点超过一定的数目则这个窗口中心可以成为一个中心
- 若参加聚类的像素点数目存在量级差别,则不是一张图?
- 如果初始的质心有较大不同,则说明两个文字有较大可能不同?
- 是否可以不识别文字,直接人眼来分类? 这就是后面的 imgTrain
汉字特征提取
- 只识别其中一个字,就可以识别整个词语?
- https://www.zhihu.com/question/49909565
开源项目 Bug
- imgo 的计算灰度图算法,应该取 rgb 三色平均,而实际上它取的是 rga
- goleveldb iterator 返回的 key 不是复制出来的,而是缓存地址,这可能导致误用。
已废弃的参考
- libsvm 解决的问题是,利用特征数据进行训练得到模型,之后进行预测
- caffe 可以用来提供图处的特征 https://www.leiphone.com/news/201708/ZKsGd2JRKr766wEd.html
- 高斯平滑算法
- 图片边缘化?
- 汉字常用特征的提取方法详解 http://blog.csdn.net/jy02660221/article/details/52012543
- 如何计算图像一阶微分参见这里:http://blog.csdn.net/jia20003/article/details/7562092
- opencv2: 下载的版本是 2.4.9 ,已经编译好的几个版本是:VC10, VC11, VC12,而自己只有 VC9,在此情况下,需要自己编译出 VC9 的版本。下载 CMake 工具,按教程重新编译。完了之后 Debug 和 Release 各编译出一个版本。 生成的 dll ,名字后面带 d 的是 debug 版本,不带 d 的是 release 版本。相应模式的应用程序在使用 opencv2 库时要注意选择正确。
- 判断字形作为特征:左右结构,上下结构,封装结构,等等,